Java 集合
集合概述
为了保存数量不确定的数据,以及保存具有映射关系的数据,Java 提供了集合类。集合类主要负责保存、盛装其他数据,因此集合类也被称为容器类。所有的集合都位于java.util包下
Java 的集合类主要由两个接口派生而出:Collection和Map,Collection和Map 是 Java 集合框架的根接口,这两个接口又包含了一些子接口或实现类
Collection 接口、子接口及其实现类的继承树

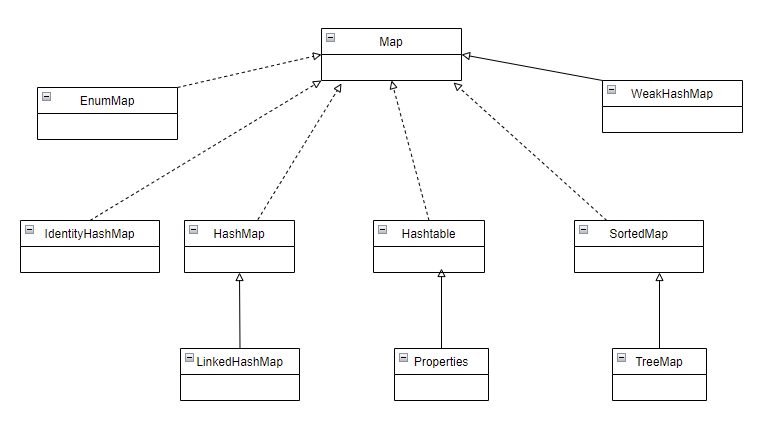
Map 继承树
Collection
Collection 接口是 List、Set 和 Queue 接口的父接口,该接口里定义的方法既可用于操作Set集合,也可用于操作 List 和 Queue 集合。
常用方法
boolean add(Object o)该方法用于向集合里添加一个元素,如果集合对象被改变了,则返回 trueboolean addAll(Colleaction c)把集合c 力的所有元素添加到指定集合里,如果集合对象被改变了,则返回 truevoid clear()清除集合里的所有元素, 将集合长度变为 0boolean contains(Object)返回集合里是否包含指定元素boolean containsAll(Collection c)返回集合里是否包含集合c 力的所有元素boolean isEmpty()返回集合是否为空Iterator iterator()返回一个Iterator对象,用于遍历集合里的元素boolean remove(Object o)删除集合中的指定元素 o,如果包含了一个或多个元素 o,只删除第一个符合条件的元素boolean removeAll(Collection c)从集合中删除集合 c 里包含的所有元素boolean retainAll(Collection c)从集合中上演出 集合c 里不包含的元素int size()该方法返回集合里元素的个数Object[] toArray()该方法把集合转成一个数组,所有的集合元素变成对应的数组元素boolean removeIf(Predicate<? super E> filter)通过Lambda表达式 批量删除符合filter条件的所有元素
集合遍历
使用 Lambda 表达式遍历集合
Java 8 为 Iterable 接口提供了一个 forEach(Consumer action) 默认方法, 该方法所需参数的类型是一个函数式接口, 而Iterable 接口是Collection 接口的父接口, 因此 Collection 集合也可直接调用该方法
Set books = new HashSet();
books.add("三国演义");
books.add("红楼梦");
books.add("西游记");
books.add("水浒传");
books.forEach(e -> {
System.out.println(e);
});
使用 Iterator 遍历集合元素
Iterator 接口也是 Java 集合框架的成员,但它与Collection 系列、Map 系列的集合不一样:Collection系列集合、Map 系列集合主要用于盛装其他对象,而Iterator 则主要用于遍历(即迭代访问)Collection集合中的元素,Iterator 也被称为迭代器
Iterator 接口里定义了如下4个方法
boolean hasNext()如果被迭代的集合元素还没有被遍历完,则返回trueObject next()返回集合里的下一个元素void remove()删除集合里上一次next 方法返回的元素void forEachRemaining(Consumer action)使用 Lambda 表达式来遍历集合元素(Java 8新增)
Set books = new HashSet();
books.add("三国演义");
books.add("红楼梦");
books.add("西游记");
books.add("水浒传");
// 获取books 集合对应的迭代器
Iterator iterator = books.iterator();
while (iterator.hasNext()){
String book = (String) iterator.next();
System.out.println(book);
if(book.equals("红楼梦")){
iterator.remove();
}
}
System.out.println(books);
当使用 Iterator 迭代访问 Collection 集合元素时,Collection 集合里的元素不能被改变,只有通过 Iterator的
remove()方法删除上一次next()方法返回的集合元素才可以; 否则将会引发java.util.ConcurrentModificationException异常
使用 Iterator 提供的forEachRemaining(Consumer action) 方法来遍历
Java 8 为 Iterator 新增了一个forEachRemaining(Consumer action) 方法, 该方法所需的 Consumer 参数同样也是函数式接口
iterator.forEachRemaining(obj -> {
System.out.println(obj);
});
使用 foreach 循环遍历集合元素
for(Object book : books){
System.out.println(book);
}
Enumeration
Enumeration 接口时Iterator 迭代器的“古老版本”,从JDK 1.0 就已经存在了,此接口只有两个方法
-
boolean hasMoreElements()如果此迭代器还有剩下的元素,则返回true -
Object nextElement()返回该迭代器的下一个元素,如果还有的话(否则抛出异常)
Enumeration 接口可用于遍历Hashtable 、Vector,以及另一个极少使用的BitSet 等"古老"的集合类
public class EnumerationTest {
public static void main(String[] args) {
Vector vector = new Vector();
vector.add("三国演义");
vector.add("红楼梦");
Hashtable scores = new Hashtable();
scores.put("语文",23);
scores.put("数学",33);
Enumeration vectorEnumeration = vector.elements();
while (vectorEnumeration.hasMoreElements()){
System.out.println(vectorEnumeration.nextElement());
}
Enumeration scoresEnumeration = scores.keys();
while (scoresEnumeration.hasMoreElements()){
Object key = scoresEnumeration.nextElement();
System.out.println(key + "-->" + scores.get(key));
}
}
}
输出
三国演义
红楼梦
语文-->23
数学-->33
Java 之所以要保留
Enumeration接口,主要是为了照顾以前那些“古老”的程序,因此如果现在编写 Java 程序,应该尽量采用Iterator迭代器
使用 Stream 操作集合
Java 8新增了Stream、IntStream,LongStream,DoubleStream等流式API,这些API代表多个支持串行和并行聚集操作的元素
Java 8 还未上面每个流式 API 提供了对应的 Builder,例如 Stream.Builder、IntStream.Builder等,开发者可以通过这些Builder来创建对应的流
IntStream is = IntStream.builder()
.add(50)
.add(20)
.add(33)
.build();
System.out.println("is最大值:" + is.max().getAsInt());
System.out.println("is最小值:" + is.min().getAsInt());
System.out.println("is元素数量:" + is.count());
System.out.println("is平均值:" + is.average());
常用方法
Stream 提供了大量的方法进行聚集操作,这些方法既可以是”中间的“(intermediate),也可以是”末端的“(terminal)
- 中间方法:中间操作允许流保持打开状态,并允许直接调用后续方法
- 末端方法:末端方法是对流的最终操作。当对某个Stream执行末端方法后,该流将会被”消耗“且不可再用
中间方法
filter(Predicate predicate)过滤 Stream 中所有不符合 predicate 的元素mapToXxx(ToXxxFunction mapper)使用ToXxxFunction对流中的元素执行一对一的转换,该方法返回的新流中包含了ToXxxFunction转生生成的所有元素peek(Consumer action)一次对每个元素执行一些操作,该方法返回的流与原有流包含相同的元素distinct()该方法用于排序流中所有重复的元素(判断重复的标准是使用equals()比较)sorted()该方法用于保证流中的元素在后续访问中处于有序状态limit(long maxSize)该方法用于保证对该流的后续访问中最大允许访问的元素个数
末端方法
forEach(Consumer action)遍历流中所有元素,对每个元素执行 actiontoArray()将流中所有元素转换为一个数组reduce()合并流中的元素min()返回流中的最小值max()返回流中的最大值count()返回流中的所有元素的数量anyMatch(Predicate predicate)判断流中是否至少包含一个元素符合Predicate 条件allMatch(Predicate predicate)判断流中是否每个元素都符合Predicate 条件noneMatch(Predicate predicate)判断流中是否所有元素都不符合Predicate条件findFirst()返回流中的第一个元素findAny()返回流中的任意一个元素
操作集合
Collection 接口提供了一个stream()默认方法,该方法可返回该集合对应的流,可通过流式API来操作集合元素
Set books = new HashSet();
books.add("三国演义");
books.add("红楼梦");
books.add("西游记");
books.add("水浒传");
System.out.println("书名小于四个字的数量:" +
books.stream().filter(ele -> ((String) ele).length() < 4).count());
System.out.println("依次输出各书的书名字数");
books.stream()
.mapToInt(ele -> ((String) ele).length())
.forEach(ele -> System.out.println(ele));
books.stream().forEach(ele -> System.out.println(ele));
书名小于四个字的数量:3
依次输出各书的书名字数
3
4
3
3
水浒传
三国演义
红楼梦
西游记
Set 集合
Set 集合和 Collection 基本相同,没有提供任何额外的方法,不同的是,Set集合不允许包含相同的元素,且通常不能记住元素的添加顺序,如果尝试添加相同的元素,add()方法将会返回false,且新元素不会被加入
HashSet 类
HashSet 是 Set 接口的典型实现,大多是时候使用 Set 集合时就是使用这个实现类。HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取和查找性能
HashSet 具有以下特点
- 不能保证元素的排列顺序
- HashSet 不是同步的,如果有多个线程同时修改HashSet集合,需通过代码来保证同步
- 集合元素值可以时null
当向 HashSet 集合中存入一个元素时, HashSet 会调用该对象的 hashCode() 方法来得到该对象 hashCode值,然后根据该hashCode 值局的顶该对象在HashSet 中的存储位置。如果有两个元素通过equals() 方法比较返回true,但它们的hashCode() 方法返回值不相等,HashSet 将会把它们存储在不同的位置,依然可以添加成功
就是说,HashSet 集合判断两个元素相等的标准是通过equals()和hashCode()方法来比较是否相等
public class A {
@Override
public boolean equals(Object obj) {
return true;
}
}
public class B {
@Override
public int hashCode() {
return 1;
}
}
public class C {
@Override
public int hashCode() {
return 2;
}
@Override
public boolean equals(Object obj) {
return true;
}
}
public class HashSetTest {
public static void main(String[] args) {
Set set = new HashSet();
set.add(new A());
set.add(new A());
set.add(new B());
set.add(new B());
set.add(new C());
set.add(new C());
System.out.println(set);
}
}
输出
[SetDemo.B@1, SetDemo.B@1, SetDemo.C@2, SetDemo.A@4554617c, SetDemo.A@1b6d3586]
因为两个C对象
equals()和hashCode()返回总是一致,因此set集合中只添加了一次
LinkedHashSet 类
LinkedHashSet 是HashSet的子类,同样根据hashCode 值来决定元素的存储位置,但它同时使用链表维护元素的次序,因此当遍历LinkedHashSet集合时,将会按照元素的添加顺序来访问集合里的元素
有序需要维护元素的插入顺序,因此性能会略低HashSet的性能,但在迭代访问时将有很好的性能,以为它以链表来维护内部顺序
public class LinkedHashSetTest {
public static void main(String[] args) {
LinkedHashSet books = new LinkedHashSet();
books.add("三国演艺");
books.add("红楼梦");
books.add("西游记");
books.add("水浒传");
System.out.println(books);
}
}
[三国演艺, 红楼梦, 西游记, 水浒传]
TreeSet
TreeSet 是SortedSet接口的实现类,正如SortedSet名字所暗示的,TreeSet可以确保集合元素处于排序状态。
与HashSet相比,TreeSet 还提供了如下几个额外的方法
Comparator comparator()如果TreeSet采用了定制排序,则该方法返回定制排序所使用的Comparator; 如果TreeSet采用了自然排序,则返回nullObject first()返回集合中的第一个元素Object last()返回集合中的最后一个元素Object lower(Object e)返回集合小位于指定元素的元素中最接近指定元素的元素Object higher(Object e)返回集合中大于指定元素的元素中最接近指定元素的元素SortedSet subSet(Object fromElement, Object toElement)返回此Set的子集合范围从fromElement(包含)到toElement(不包含)SortedSet headSet(Object toElement)返回此Set的子集,由小于toElement的元素组成SortedSet tailSet(Object fromElement)返回此Set的自己,由大于或等于fromElement的元素组成
public class TreeSetTest {
public static void main(String[] args) {
TreeSet set = new TreeSet();
set.add(20);
set.add(30);
set.add(25);
set.add(2);
set.add(9);
System.out.println("输出9-25区间的元素:" + set.subSet(9, 25));
System.out.println("输出小于25的元素:" + set.headSet(25));
System.out.println("输出小于10并最接近10的元素:" + set.lower(10));
System.out.println("输出最后一位元素:" + set.last());
}
}
输出
输出9-25区间的元素:[9, 20]
输出小于25的元素:[2, 9, 20]
输出小于10并最接近10的元素:9
输出最后一位元素:30
自然排序
TreeSet 会调用集合元素的compareTo(Object obj) 方法来比较元素之间的大小关系,然后将集合元素按升序排列,这种方式就是自然排序
自然排序中, TreeSet集合元素必须实现Comparable 接口。Java 的一些常用类已经实现了Comparable 接口,并提供了比较大小的标准。
BigDecimal、BigInteger以及所有的数值类型对应的包装类 :按它们对应的数值大小进行比较Character按字符的Unicode值进行比较Booleantrue 大于 falseString依次比较字符串中每个字符的Unicode值Date、Time后面的时间、日期比前面的时间、日期大
大部分类在实现
compareTo(Object obj)方法时,都需要将被比较对象obj强制类型转换成相同类型,如果希望TreeSet正常运转,最好只添加同一种类型的对象
定制排序
如果需要实现定制排序,则需要在创建TreeSet 集合对象时,提供一个Comparator 对象与该TreeSet集合关联,由该Comparator 对象负责集合元素的排序逻辑。由于Comparator 是一个函数式接口,因此可使用Lambda 表达式来代替Comparator 对象
public class M {
int age;
public M(int age) {
this.age = age;
}
@Override
public String toString() {
return "M [age:" + age + "]";
}
}
public class TreeSetCustomSortTest {
public static void main(String[] args) {
// age 越大,M对象越小
TreeSet set = new TreeSet(((o1, o2) -> {
M m1 = (M) o1;
M m2 = (M) o2;
return m1.age > m2.age ? -1 : m1.age < m2.age ? 1 : 0;
}));
set.add(new M(15));
set.add(new M(20));
set.add(new M(10));
set.add(new M(19));
System.out.println(set);
}
}
输出
[M [age:20], M [age:19], M [age:15], M [age:10]]
EnumSet 类
EnumSet 时专门为枚举设计的集合类,EnumSet 中的所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet 时显式或隐式地指定
EnumSet有以下特点
EnumSet的集合元素是有序的,EnumSet以枚举值在Enum类内的定义顺序来决定集合元素的顺序EnumSet在内部以位向量的形式存储,这种存储方式非常紧凑、高效,因此EnumSet对象占用内存很小,而且运行效率很好EnumSet集合不允许接入null元素,如果试图插入null元素,EnumSet将抛出NullPointerException异常
EnumSet没有暴漏任何构造器来创建该类的实例,只能通过静态方法来创建对象,EnumSet类提供了如下常用的静态方法来创建EnumSet对象
EnumSet allOf(Class elementType)创建一个包含指定枚举类里所有枚举值的EnumSet集合EnumSet complementOf(EnumSet s)创建一个其元素类型与指定EnumSet里元素类型相同的EnumSet集合,新EnumSet集合包含原EnumSet集合所不包含的、此枚举类剩下的枚举值EnumSet copyOf(Collection c)使用一个普通集合来创建EnumSet集合EnumSet copyOf(EnumSet s)创建一个与指定EnumSet具有相同元素类型,相同元素集合元素的EnumSet集合EnumSet noneOf(Class elementType)创建一个元素类型为指定枚举类型的空EnumSetEnumSet of(E first,E... rest)创建一个包含一个或多个枚举值的EnumSet集合,传入的多个枚举值必须属于同一个枚举类EnumSet range(E from,E to)创建一个包含从from枚举值到to枚举值范围内所有枚举值的EnumSet集合
public class EnumSetTest {
public static void main(String[] args) {
EnumSet es1 = EnumSet.allOf(Season.class);
System.out.println("es1:" + es1);
EnumSet es2 = EnumSet.noneOf(Season.class);
System.out.println("es2:" + es2);
es2.add(Season.FALL);
es2.add(Season.SPRING);
System.out.println("es2:" + es2);
EnumSet es3 = EnumSet.of(Season.SPRING,Season.FALL);
System.out.println("es3:" + es3);
EnumSet es4 = EnumSet.range(Season.SPRING,Season.FALL);
System.out.println("es4:" + es4);
EnumSet es5 = EnumSet.complementOf(es4);
System.out.println("es5:" + es5);
EnumSet es6 = EnumSet.copyOf(es4);
System.out.println("es6:" + es6);
HashSet hashSet = new HashSet();
hashSet.add(Season.WINTER);
hashSet.add(Season.FALL);
EnumSet es7 = EnumSet.copyOf(hashSet);
System.out.println("es7:" + es7);
HashSet books = new HashSet();
books.add("三国演义");
books.add("红楼梦");
EnumSet es8 = EnumSet.copyOf(books);
System.out.println("es8:" + es8);
}
}
es1:[SPRING, SUMMER, FALL, WINTER]
es2:[]
es2:[SPRING, FALL]
es3:[SPRING, FALL]
es4:[SPRING, SUMMER, FALL]
es5:[WINTER]
es6:[SPRING, SUMMER, FALL]
es7:[FALL, WINTER]
Exception in thread "main" java.lang.ClassCastException: java.lang.String cannot be cast to java.lang.Enum
at java.util.EnumSet.copyOf(EnumSet.java:176)
at SetDemo.EnumSetTest.main(EnumSetTest.java:33)
各 Set 实现类的性能分析
TreeSet 需要额外的红黑树算法来维护元素的次数,因此性能低于HashSet。只有需要一个保持排序的 Set时,才应该使用TreeSet
LinkedHashSet 是HashSet的子类,对于普通的插入,删除操作,LinkedHashSet要比HashSet略微慢一点,这是由于维护链表所带来的额外开销造成的,但由于有了链表,遍历LinkedHashSet 会更快
EnumSet 是所有 Set 实现类中性能最好的,但它只能保存同一个枚举类的枚举值作为集合元素
HashSet,TreeSet,EnumSet都是线程不安全的,如果有多线程同时操作该Set集合,则必须手动从代码上保证Set集合的同步性
List 集合
List 集合代表一个元素有序、可重复的集合,集合中的每个元素都有其对应的顺序索引。List 集合允许使用重复元素,可以通过索引来访问指定位置的集合元素。 List 集合默认按元素的添加顺序设置元素的索引
List 接口
List 作为 Collection 接口的子接口,可以使用 Collection 接口里的全部方法。由于List 是有序集合,因此 List 集合里增加了一些根据索引来操作集合元素的方法
add(int index, Object element)将元素element插入到List集合的index处boolean add(int index,Collection c)将集合c所包含的所有元素都插入到List集合的index处Object get(int index)返回集合index索引处的元素int indexOf(Object o)返回对象o在List集合中第一次出现的位置索引int lastIndexOf(Object)返回对象o在List集合中最后一次出现的位置索引Object remove(int index)删除并返回index索引处的元素Object set(int index,Object element)将index索引处的元素替换成element对象, 返回被替换的旧元素List subList(int fromIndex,int toIndex)返回从索引fromIndex(包含)到索引toIndex(不包含)处所有集合元素组成的子集合
除此之外, Java 8 还为List添加了如下两个默认方法
void replaceAll(UnaryOperator operator)根据operator指定的计算规则重新设置List 集合的所有元素void sort(Comparator c)根据Comparator 参数对List 集合的元素排序
public class ListTest {
public static void main(String[] args) {
List books = new ArrayList();
books.add("三国演义");
books.add("红楼梦");
books.add("西游记");
for (int i = 0; i < books.size(); i++) {
System.out.println(books.get(i));
}
// 将 水浒传 插入到索引为2的位置
books.add(2, "水浒传");
System.out.println("books.add(2,\"水浒传\"):" + books);
books.remove(3);
System.out.println("books.remove(3):" + books);
System.out.println("books.indexOf(new String(\"红楼梦\")):" + books.indexOf(new String("红楼梦")));
books.set(2, "朝花夕拾");
System.out.println("books.set(2,\"朝花夕拾\"):" + books);
System.out.println("books.subList(1, 2):" + books.subList(1, 2));
books.add("海底两万里");
books.add("钢铁是怎么炼成的");
System.out.println(books);
// 根据书名长度排序
books.sort(((o1, o2) -> ((String) o1).length() - ((String) o2).length()));
System.out.println(books);
// 将集合元素全部替换为每个元素的字符长度
books.replaceAll(ele -> ((String)ele).length());
System.out.println(books);
}
}
输出
三国演义
红楼梦
西游记
books.add(2,"水浒传"):[三国演义, 红楼梦, 水浒传, 西游记]
books.remove(3):[三国演义, 红楼梦, 水浒传]
books.indexOf(new String("红楼梦")):1
books.set(2,"朝花夕拾"):[三国演义, 红楼梦, 朝花夕拾]
books.subList(1, 2):[红楼梦]
[三国演义, 红楼梦, 朝花夕拾, 海底两万里, 钢铁是怎么炼成的]
[红楼梦, 三国演义, 朝花夕拾, 海底两万里, 钢铁是怎么炼成的]
[3, 4, 4, 5, 8]
List 判断两个对象相等是通过
equals()方法进行判断
List 除了iterator() 方法之外,还额外提供了listIterator() 方法,该方法返回一个ListIterator 对象,ListIterator 接口继承了 Iterator 接口,提供了转没操作List的方法。 ListIterator 接口在Iterator 接口基础上增加了如下的方法
boolean hasPrevious()返回该迭代器关联的集合是否还有上一个元素Object previous()返回迭代器的上一个元素void add(Object o)在指定位置插入一个元素
public class ListIteratorTest {
public static void main(String[] args) {
List books = new ArrayList();
books.add("三国演义");
books.add("红楼梦");
books.add("西游记");
ListIterator iterator = books.listIterator();
while (iterator.hasNext()){
String book = (String) iterator.next();
System.out.println(book);
if(book.equals("红楼梦")){
iterator.add("水浒传");
}
}
System.out.println("-----分割线-------");
while (iterator.hasPrevious()){
String book = (String) iterator.previous();
System.out.println(book);
}
}
}
输出
三国演义
红楼梦
西游记
-----分割线-------
西游记
水浒传
红楼梦
三国演义
ArrayList
ArrayList 是List的典型实现类,完全支持上面介绍的List 接口的全部功能
ArrayList 是基于数组实现的List 类,通过使用initialCapacity 参数来设置该数组的长度,当向ArrayList 添加元素超出数组的长度时,initialCapacity 会自动增加
通常无需关心initalCapacity,但如果要添加大量元素时,可使用ensureCapacity(int minCapacity)方法一次性增加initalCapacity。这样可以减少重新分配次数,从而提高性能,如果一开就知道集合需要保存多少元素,则可以在创建时就通过ArrayList(int initialCapacity) 指定initalCapacity
除此之外ArrayList 还提供了void trimToSize() 方法,用于调整数组长度为当前元素的个数,可以减少集合对象占用的存储空间
LinkedList
LinkedList 类是 List 接口的实现类,除此之外,LinkedList 还实现了Deque接口,可以被当成双端队列来使用,因此既可以被当成“栈” 来使用,也可以当成队列来使。
public class LinkedListTest {
public static void main(String[] args) {
LinkedList books = new LinkedList();
// 将字符串元素即入队列的尾部
books.offer("三国演义");
// 将一个字符串元素加入栈的顶部
books.push("西游记");
// 将字符串元素添加到队列的头部 相当于栈的顶部
books.offerFirst("朝花夕拾");
// 按索引访问来遍历元素
for (int i = 0; i < books.size(); i++) {
System.out.println("遍历中:" + books.get(i));
}
// 访问并不删除顶栈的元素
System.out.println(books.peekFirst());
// 访问并不删除队列的最后一个元素
System.out.println(books.peekLast());
// 将栈顶的元素弹出"栈"
System.out.println(books.pop());
System.out.println(books);
// 访问并删除队列的最后一个元素
System.out.println(books.pollLast());
System.out.println(books);
}
}
输出
遍历中:朝花夕拾
遍历中:西游记
遍历中:三国演义
朝花夕拾
三国演义
朝花夕拾
[西游记, 三国演义]
三国演义
[西游记]
Vector
Vector 是一个古老的集合(从JDK1.0 就有了),在用法上和ArrayList 几乎完全相同,同样是基于数组实现的List类,Vector 具有很多缺点,通常尽量少用 Vector,这里了解即可
与ArrayList 不同的是,Vector 是线程安全的,因此性能也低于ArrayList
public class VectorTest {
public static void main(String[] args) {
Vector books = new Vector();
books.add("三国演义");
// Vector 原有方法 与Add()一致
books.addElement("红楼梦");
books.add("西游记");
for (int i = 0; i < books.size(); i++) {
System.out.println(books.get(i));
}
// 将 水浒传 插入到索引为2的位置
books.add(2, "水浒传");
System.out.println("books.add(2,\"水浒传\"):" + books);
books.remove(3);
System.out.println("books.remove(3):" + books);
System.out.println("books.indexOf(new String(\"红楼梦\")):" + books.indexOf(new String("红楼梦")));
books.set(2, "朝花夕拾");
System.out.println("books.set(2,\"朝花夕拾\"):" + books);
System.out.println("books.subList(1, 2):" + books.subList(1, 2));
books.add("海底两万里");
books.add("钢铁是怎么炼成的");
System.out.println(books);
// 根据书名长度排序
books.sort(((o1, o2) -> ((String) o1).length() - ((String) o2).length()));
System.out.println(books);
// 将集合元素全部替换为每个元素的字符长度
books.replaceAll(ele -> ((String)ele).length());
System.out.println(books);
}
}
输出
三国演义
红楼梦
西游记
books.add(2,"水浒传"):[三国演义, 红楼梦, 水浒传, 西游记]
books.remove(3):[三国演义, 红楼梦, 水浒传]
books.indexOf(new String("红楼梦")):1
books.set(2,"朝花夕拾"):[三国演义, 红楼梦, 朝花夕拾]
books.subList(1, 2):[红楼梦]
[三国演义, 红楼梦, 朝花夕拾, 海底两万里, 钢铁是怎么炼成的]
[红楼梦, 三国演义, 朝花夕拾, 海底两万里, 钢铁是怎么炼成的]
[3, 4, 4, 5, 8]
Vector 还提供了一个Stack 子类,用于模拟”栈“这种数据结构(后进先出)
Object peek()返回”栈“的第一个元素, 但并不将该元素”pop“ 出栈Object pop()返回”栈“的第一个元素, 并将该元素”pop“ 出栈Object push(Object item)将一个元素”push“进栈,最后一个进”栈“的元素总是位于”栈“顶
public class StackTest {
public static void main(String[] args) {
Stack stack = new Stack();
stack.push("张三");
stack.add("李四");
stack.add("王五");
stack.push("赵六");
System.out.println(stack);
System.out.println(stack.peek());
System.out.println(stack);
System.out.println(stack.pop());
System.out.println(stack);
System.out.println(stack.pop());
System.out.println(stack);
}
}
输出
[张三, 李四, 王五, 赵六]
赵六
[张三, 李四, 王五, 赵六]
赵六
[张三, 李四, 王五]
王五
[张三, 李四]
由于
Stack继承了Vctor,因此它也是一个非常古老的Java 集合类,它同样是线程安全的、性能较差的,因此应该尽量少用Stack类。 如果需要使用”栈“这种数据接口,建议使用ArrayDeque代替它
Queue 集合
Queue 用于模拟队列这种数据结构,队列通常指”先进先出“(FIFO)的容器。新元素插入(offer)到队列的尾部,访问元素(poll)操作会返回队列头部的元素。通常,队列不允许随机访问队列中的元素
Queue 接口中定义了如下几个方法
void add(Object e)见通过指定元素加入此队列的尾部Object element()获取队列头部的元素,但是不删除该元素boolean offer(Object e)将指定哦元素加入此队列的尾部。当使用有容量限制的队列时,此方法通常比add(Object e)好Object peek()获取队列头部的元素, 但是不删除该元素。 如果此队列为空, 则返回nullObject poll()获取队列头部的元素,并删除该元素
PriorityQueue 实现类
PriorityQueue 是一个特殊队列,即优先队列。 优先队列的作用是能保证每次取出的元素都是队列中权值最小的。因此当调用peek() 方法或者poll() 方法取出队列中的元素时,并不是取出最先进入队列的元素,而是取出队列中最小的元素
public class PriorityQueueTest {
public static void main(String[] args) {
PriorityQueue pq = new PriorityQueue();
pq.offer(20);
pq.offer(33);
pq.offer(15);
pq.offer(23);
for (int i = 0; i < 4; i++) {
System.out.println(pq.poll());
}
}
}
输出
15
20
23
33
PriorityQueue 不允许插入 null 元素,它还需要对队列元素进行排序,PriortyQueue 的元素有两种排序方式
- 自然排序:采用自然顺序的
PriorityQueue集合中的元素必须实现了Comparable接口,而且应该是同一个类的多个实例,否则可能导致ClassCastException异常 - 定制排序:创建
PriorityQueue队列时,传入一个Comparator对象,该对象负责对队列中的所有元素进行排序。采用定制排序时不要求队列元素实现Comparable接口
Deque 接口
Deque 接口时Queue 接口的子接口,它代表一个双端队列,Deque 接口里定义了一些双端队列的方法,这些方法允许从两端来操作队列的元素
void addFirst(Object e)将指定元素插入该双端队列的开头void addLast(Object e)将指定元素插入该双端队列的末尾Iterator descendingIterator()返回该双端队列对应的迭代器,该迭代器将以你想顺序来迭代队列中的元素Object getFirst()获取但不删除双端队列的第一个元素Object getLast()获取但不删除双端队列的最后一个元素boolean offerFirst(Object e)将指定元素插入该双端队列的开头boolean offerLast(Object e)将指定元素插入该双端队列的末尾Object peekFirst()获取但不删除该双端队列的第一个元素;如果此双端队列为空,则返回nullObject peekLast()获取但不删除该双端队列的最后一个元素;如果此双端队列为空,则返回nullObject pollFirst()获取并删除该双端队列的第一个元素;如果此双端队列为空,则返回nullObject pollLast()获取并删除该双端队列的最后一个元素;如果此双端队列为空,则返回nullObject pop()pop出双对队列所表示的栈的栈顶元素。相当于removeFirst()(栈方法)void push(Object e)将一个元素 push进该双端队列所表示的栈的栈顶 (栈方法)Object removeFirst()获取并删除该双端队列的第一个元素Object removeFirstOccurrence(Object o)删除该双端队列的第一次出现的元素oObject removeLast()获取并删除该双端队列的最后一个元素boolean removeLastOccurrence(Object o)删除该双端队列的最后一次出现的元素o
从以上方法可以看到,Deque 不仅可以当成双端队列使用,而且可以被当成栈来使用,因为该类里还包含了pop(出栈)、push(入栈) 两个方法
ArrayDeque 类
ArrayDeque 是Deque的实现类,从名称可以看出,它是一个基于数组实现的双端队列,创建Deque 时同样可指定一个numElements 参数,该参数用于指定 Object[] 数组的长度;如果不指定,Deque底层数组的长度为16
将ArrayDeque 当作栈来使用
public class ArrayDequeStack {
public static void main(String[] args) {
ArrayDeque stack = new ArrayDeque();
stack.push("三国演义");
stack.push("西游记");
stack.push("朝花夕拾");
System.out.println(stack);
// 取队列头部的元素, 但是不删除该元素
System.out.println(stack.peek());
// 出栈
System.out.println(stack.pop());
System.out.println(stack);
}
}
[朝花夕拾, 西游记, 三国演义]
朝花夕拾
朝花夕拾
[西游记, 三国演义]
将ArrayDeque 当作队列来使用
public class ArrayDequeQueue {
public static void main(String[] args) {
ArrayDeque queue = new ArrayDeque();
queue.offer("三国演义");
queue.offer("西游记");
queue.offer("朝花夕拾");
System.out.println(queue);
// 取队列头部的元素, 但是不删除该元素
System.out.println(queue.peek());
// poll 出第一个元素
System.out.println(queue.poll());
System.out.println(queue);
}
}
[三国演义, 西游记, 朝花夕拾]
三国演义
三国演义
[西游记, 朝花夕拾]
Map 集合
Map 用于保存具有映射关系的数据,因此Map 集合里保存着两组值,一组用于保存Map 里的key,另外一组值用于保存Map里的value, Map 的 key 不允许重复
key 和 value 之间存在单向一对一关系,即通过指定的key,总能找到唯一的、确定的value
Map 接口中定义了如下常用的方法
void clean()删除该Map对象中所有的key-value对boolean containsKey(Object key)查询Map中是否包含指定的key,如果包含则返回trueSet entrySet()返回Map中所包含的key-value所组成的Set集合,每个集合元素都是Map.Entry对象Object get(Object key)返回指定key所对应的value; 如果Map不包含此key,则返回nullboolean isEmpty()查询该Map是否为空Set keySet返回该Map中所有key组成的Set集合Object put(Object key,Object value)添加一个key-value对,如果当前Map中已有一个与该key相等的key-value对,则新的key-value对会覆盖原来key-value对void putAll(Map m)将指定Map中的key-value对复制到本Map中Object remove(Object key)删除指定key所对应的key-value对,返回被删除key所关联的value,如果key不存在则返回nullboolean remove(Object key,Object value)删除指定key、value所对应的key-value对,如果成功删除,则返回true。(Java 8新增)int size()返回该Map里的key-value对的个数Collection values()返回该Map 里所有value组成的Collection
Map 中包括一个内部类Entry,该类封装了一个key-value对。 Entry含有如下三个方法
Object getKey()返回该Entry里包含的key值Object getValue()返回该Entry里包含的value值Object setValue(V value)设置该Entry里包含的value值,并返回新设置的value值
public class MapTest {
public static void main(String[] args) {
Map map = new HashMap();
map.put("三国演义", 25);
map.put("朝花夕拾", 33);
map.put("红楼梦", 62);
// key重复,会把value覆盖上去而不是新增
map.put("红楼梦", 99);
// 如果新value覆盖了原有的value,该方法返回被覆盖的value
System.out.println(map.put("朝花夕拾", 1));
System.out.println(map);
System.out.println("是否包含key为三国演义:" + map.containsKey("三国演义"));
System.out.println("是否包含值为99的value:" + map.containsValue(99));
// 遍历map所有key集合
for (Object key : map.keySet()) {
System.out.println(key + "-->" + map.get(key));
}
// 根据key删除key-value对
map.remove("三国演义");
System.out.println(map);
}
}
输出
33
{三国演义=25, 红楼梦=99, 朝花夕拾=1}
是否包含key为三国演义:true
是否包含值为99的value:true
三国演义-->25
红楼梦-->99
朝花夕拾-->1
{红楼梦=99, 朝花夕拾=1}
Java8 为 Map 新增的方法
Java 8除了为Map 增加了remove(Object key,Object value) 默认方法以外,还增加了如下方法
Object compute(Object key,BiFunction remappingFunction)该方法使用remappingFunction根据原key-value对计算一个新value。只要新value不为null,就使用新value覆盖原value;如果原value不为null,但新value为null,则删除原key-value对;如果原value新value都为null, 那么该方法不改变任何key-value对,直接返回`null``Object computeIfAbsent(Object key, Function mappingFunction)如果传给该方法的key参数在Map中对应的value为null,则使用mappingFunction根据key计算一个新的结果,如果计算结果不为null,则用计算结果覆盖原有的value。如果原Map不包括该key,那么该方法会添加一组key-value对;(如果key对应的value不为null,不做任何操作)Object computeIfPresent(Object key,Bifunction remappingFunction)如果传给该方法的key参数在Map中对应的value不为null,该方法将使用remappingFunction根据原key、value计算一个新的结果,如果计算结果不为null,则使用该结果覆盖原来的value;如果结算结果为null,则删除原key-value对void forEach(BiConsumer action)可通过Lambda 遍历key-value对Object getOrDefault(Object key,V defaultValue)获取指定 key 对应的 value。如果key不存在,则返回defaultValueObject merge(Object key,Object value,BiFunction remappingFunction)该方法会现根据key 参数获取该Map 中对应的value。如果获取到的value为null,则直接用传入的value覆盖原有的value(如果key不存在,会添加一组key-value);如果获取的value不为null,则使用remappingFunction函数根据原value,新value计算一个新的结果,并用得到的结果覆盖原有的valueObjcet putIfAbsent(Object key,Object value)该方法会自动检测指定key对应的value是否为null,如果该key对应的value为null,该方法将会用新value代替原来的null值,如果key不存在,则会添加新的key-value对Object replace(Object key,Object value)将Map中指定key对应的value替换成新value。如果key不存在不会添加新的key-value对,并返回nullboolean replace(K key,V oldValue,V newValue)将 Map中指定key-value对的原value替换成新value。如果在Map中找到指定的key-value对,则执行替换并返回true,否则返回falseboolean replaceAll(BiFunction function)该方法使用BiFunction对原key-value对执行计算,并将计算结果作为该key-value对的value值
public class MapTest2 {
public static void main(String[] args) {
Map map = new HashMap();
map.put("三国演义", 25);
map.put("朝花夕拾", 33);
map.put("红楼梦", 62);
map.put("海底两万里", null);
map.replace("红楼梦", 20);
System.out.println(map);
// 修改海底两万里的值,因为其值是null 所以直接用32覆盖到value上
map.merge("海底两万里", 32, (oldVal, par) -> {
return 30;
});
System.out.println(map);
// 修改海底两万里的值,因为其值不是null,所以通过 Lambda 计算两个value的值,将结果覆盖到此键值对的value上
map.merge("海底两万里", 32, (oldVal, par) -> {
return (int) oldVal + (int) par;
});
System.out.println(map);
// 因为新value为null 所以删除key为 红楼梦的键值对
map.compute("红楼梦", (k, v) -> {
return null;
});
System.out.println(map);
// 将key 为"海底两万里" 的值 改为该key的长度,由于key对应的value 不为null,所以这里没有变动
map.computeIfAbsent("海底两万里", key -> {
return ((String) key).length();
});
System.out.println(map);
// 将key 为"钢铁是怎样炼成的" 的值 改为该key的长度,因为集合里没有此key 所以增加了一对key-value
map.computeIfAbsent("钢铁是怎样炼成的", key -> {
return ((String) key).length();
});
System.out.println(map);
// 将key 为"海底两万里" 的值增加10
map.computeIfPresent("海底两万里", (key, value) -> {
return (Integer) value + 10;
});
System.out.println(map);
// 将key为”三国演义“并且值为0的键值对的值改为30,以下没有匹配结果所以不改变
map.replace("三国演义", 0, 30);
System.out.println(map);
// 将key为”三国演义“并且值为25的键值对的值改为30,以下有匹配结果所以改变
map.replace("三国演义", 25, 30);
System.out.println(map);
// 获取水浒传的值,如果该key不存在,则取defaultValue
System.out.println("水浒传-->" + map.getOrDefault("水浒传",3));
// 不存在此key 添加新的键值对
map.putIfAbsent("水浒传",null);
System.out.println(map);
// 水浒传的值为null 把新值覆盖到旧值上,
map.putIfAbsent("水浒传",11);
System.out.println(map);
// 水浒传的值不为null 不改动
map.putIfAbsent("水浒传",22);
System.out.println(map);
// 循环遍历
map.forEach((key, value) -> {
System.out.println(key + "-->" + value);
});
}
}
输出
{三国演义=25, 红楼梦=20, 海底两万里=null, 朝花夕拾=33}
{三国演义=25, 红楼梦=20, 海底两万里=32, 朝花夕拾=33}
{三国演义=25, 红楼梦=20, 海底两万里=64, 朝花夕拾=33}
{三国演义=25, 海底两万里=64, 朝花夕拾=33}
{三国演义=25, 海底两万里=64, 朝花夕拾=33}
{三国演义=25, 海底两万里=64, 钢铁是怎样炼成的=8, 朝花夕拾=33}
{三国演义=25, 海底两万里=74, 钢铁是怎样炼成的=8, 朝花夕拾=33}
{三国演义=25, 海底两万里=74, 钢铁是怎样炼成的=8, 朝花夕拾=33}
{三国演义=30, 海底两万里=74, 钢铁是怎样炼成的=8, 朝花夕拾=33}
水浒传-->3
{水浒传=null, 三国演义=30, 海底两万里=74, 钢铁是怎样炼成的=8, 朝花夕拾=33}
{水浒传=11, 三国演义=30, 海底两万里=74, 钢铁是怎样炼成的=8, 朝花夕拾=33}
{水浒传=11, 三国演义=30, 海底两万里=74, 钢铁是怎样炼成的=8, 朝花夕拾=33}
水浒传-->11
三国演义-->30
海底两万里-->74
钢铁是怎样炼成的-->8
朝花夕拾-->33
HashMap 和 HashTable
HashMap 和 Hashtable 都是 Map 接口的典型实现类,两者关系类似于 ArrayList 和 Vector的关系:HashTable 是一个古老的 Map 实现类,从JDK 1.0 起就已经出现了,当时,Java 还没有 Map 接口,因此它包含两个繁琐的方法,elements() (类似于values()) 和 keys()(类似于keySet())
Java 8 改进了HashMap的实现,使用HashMap 存在 key 冲突是依然具有较好的性能
此外, Hashtable 和 HashMap 存在几点区别
Hashtable是一个线程安全的Map实现, 但HashMap是线程不安全的实现类,因此,HashMap的性能更高一点Hashtable不允许使用null作为key和value, 如果试图把null值 放进Hashtable中,将会引发nullPointerException异常; 但HashMap可以使用null作为key或value- 通过
containsValue()比较两个value是否相等时,Hashtable只需要两个对象equals相等即可;HashMap不仅需要equals相等,还需要类型相同
如HashSet 不能保证元素的顺序一样,HashMap、Hashtable 也不能保证key-value 对的顺序。此外 判断key 标准也是通过equals() 方法比较返回true,并且 hashCode 值也相等
public class A {
int count;
public A(int count) {
this.count = count;
}
// 根据count 的值来判断两个对象是否相等
@Override
public boolean equals(Object obj) {
if (obj == this) {
return true;
}
if (obj != null && obj.getClass() == A.class) {
return ((A) obj).count == this.count;
}
return false;
}
// 根据count 来计算 hashCode 值
@Override
public int hashCode() {
return this.count;
}
}
public class B {
@Override
public boolean equals(Object obj) {
return true;
}
}
比较key
public class HashMapTest {
public static void main(String[] args) {
Hashtable ht = new Hashtable();
ht.put(new B(),"123");
ht.put(new A(111),"321");
System.out.println(ht.containsKey(new B()));
System.out.println(ht.containsKey(new A(111)));
HashMap map = new HashMap();
map.put(new B(),"123");
map.put(new A(111),"321");
System.out.println(map.containsKey(new B()));
System.out.println(map.containsKey(new A(111)));
}
}
输出
false
true
false
true
比较 value
public class HashMapTest {
public static void main(String[] args) {
Hashtable ht = new Hashtable();
ht.put(new A(123),"三国演义");
ht.put(new A(321),"红楼梦");
ht.put(new A(111),new B());
System.out.println(ht.containsValue("测试"));
HashMap map = new HashMap();
map.put(new A(123),"三国演义");
map.put(new A(321),"红楼梦");
map.put(new A(111),new B());
System.out.println(map.containsValue(new String("测试")));
System.out.println(map.containsValue(new B()));
}
}
输出
true
false
true
LinkedHashMap
LinkedHashMap 使用双向链表来维护元素的顺序,该链表负责维护Map的迭代顺序,迭代顺序与元素的插入顺序保持一致
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap scores = new LinkedHashMap();
scores.put("语文", 88);
scores.put("数学", 90);
scores.put("英语", 22);
scores.forEach((k, v) -> {
System.out.println(k + "-->" + v);
});
}
}
输出
语文-->88
数学-->90
英语-->22
Properties
Properties 是Hashtable的子类。该对象在处理属性文件时特别方便。Properties 类可以把Map 对象和属性文件关联起来,从而可以把Map对象中的key-value 对写入属性文件中,也可以把属性文件中的"属性名=属性值"加载到Map对象中
Properties 提供了如下方法
String getProperty(String key)获取Properties中指定属性名对应的属性值String getProperty(String key,String defaultValue)获取Properties中指定属性名对应的属性值,如果该Properties中不存在此key,则获得指定默认值Object setProperty(String key,String value)设置属性值void load(InputStream inStream)从属性文件(输入流)中加载key-value对,把加载到的key-value对追加到Properties里void store(OutputStream out,String comments)将Properties中的元素输出到指定的文件(输出流)中
public class PropertiesTest {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.setProperty("username","root");
props.setProperty("password","123456");
props.store(new FileOutputStream("a.ini"),"comment line");
Properties props2 = new Properties();
props2.load(new FileInputStream("a.ini"));
System.out.println(props2);
}
}
输出
{password=123456, username=root}
a.ini
#comment line
#Wed Sep 13 20:33:14 CST 2023
password=123456
username=root
SortedMap 接口和 TreeMap 实现类
与Set接口相似,Map 接口也派生出一个SortedMap 子接口,SortedMap 接口也有一个TreeMap 实现类
TreeMap底层通过红黑树(Red-Black tree)实现,也就意味着containsKey(), get(), put(), remove()都有着log(n)的时间复杂度。
TreeMap 也有两种排序方式
- 自然排序:
TreeMap的所有key必须实现Comparable接口,而且所有的key应该是同一个类的对象,否则将会抛出ClassCastException异常 - 定制排序:创建
TreeMap时,传入一个Comparator对象,该对象负责对TreeMap中的所有key进行排序。采用定制排序不要求Map的key实现Comparator接口
TreeMap 提供了一些列根据key顺序访问key-value对的方法
Map.Entry firstEntry()返回该Map中的最小key所对应的key-value对,如果该Map为空,则返回nullMap.Entry lastEntry()返回该Map的最大key所对应的key-value对,如果该Map为空,则返回nullObject firstKey()返回该Map中的最小key值,如通过该Map为空,则返回nullObject lastKey()返回该Map中的最大key值,如通过该Map为空,则返回nullMap.Entry higherEntry(Object key)返回该Map中位于key的后一位key-value对Map.Entry lowerEntry(Object key)返回该Map中位于key的前一位key-value对Object higherKey(Object key)返回该Map中位于key的后一位key值Object lowerKey(Object key)返回该Map中位于key的前一位key值NavigableMap subMap(Object fromKey,boolean fromInclusive,Object toKey,boolean toInclusive)返回该Map 的子Map, 其key 的范围是从fromKey(是否包括取决去第二个参数) 到toKey(是否包括取决第四个参数)SortedMap subMap(Object fromKey,Object toKey)返回该Map的子Map,其key的范围是从fromKey(包括)到toKey(不包括)SortedMap tailMap(Object fromKey)返回该Map的子Map,其key的范围是大于fromKey(包括)的所有KeyNavigableMap tailMap(Object fromKey,boolean inclusive)返回该Map的子Map,其key的范围是大于fromKey(是否包括取决于第二个参数)的所有KeySortedMap headMap(Object toKey)返回该Map的子Map,其key的范围是小于toKey(不包括)的所有keyNavigableMap headMap(Object toKey,boolean inclusive)返回该Map的子Map,其key的范围是小于toKey(是否包括取决于第二个参数)的所有key
public class TreeMapTest {
public static void main(String[] args) {
TreeMap tm = new TreeMap();
tm.put(20, "张三");
tm.put(18, "李四");
tm.put(22, "王五");
tm.put(25, "赵六");
tm.put(23, "孙七");
// 获取最小key
System.out.println("tm.firstKey():" + tm.firstKey());
// 获取最接近20并且大于20的Entry
Map.Entry entry = tm.higherEntry(20);
System.out.println(entry.getKey() + "-->" + entry.getValue());
// 获取key>=20 并且 key<=23 的map
NavigableMap nm = tm.subMap(20, true, 23, true);
System.out.println(nm);
}
}
tm.firstKey():18
22-->王五
{20=张三, 22=王五, 23=孙七}
WeakHashMap
WeakHashMap 的用法和HashMap 基本类似,但不同的是,WeakHashMap的key 只保留了实际对象的弱引用,这意味着如果没被其他强引用变量所引用,则这些key 所引用的对象可能被垃圾回收,WeakHashMap 也可能会自动删除这些key 所对应的key-value对
public class WeakHashMapTest {
public static void main(String[] args) {
WeakHashMap whm = new WeakHashMap();
String str = new String("英语");
whm.put(new String("语文"),20);
whm.put(new String("数学"),50);
// 被强引用变量引用,不会被垃圾回收
whm.put(str,30);
System.out.println(whm);
System.gc();
System.out.println(whm);
}
}
输出
{数学=50, 英语=30, 语文=20}
{英语=30}
IdentityHashMap 实现类
此类的实现机制与HashMap 基本相似,但它在处理两个key 是否相等要求 只有两个key严格相等时(key1 == key2) 才算相等
public class IdentityHashMapTest {
public static void main(String[] args) {
IdentityHashMap ihm = new IdentityHashMap();
ihm.put("语文",98);
ihm.put(new String("语文"),88);
ihm.put("Java",98);
ihm.put("Java",98);
System.out.println(ihm);
}
}
输出
{Java=98, 语文=98, 语文=88}
EnumMap 实现类
EnumMap 是一个与枚举类一起使用的Map 实现, EnumMap 中的所有key 都必须是单个枚举类的枚举值。创建EnumMap 时必须显式或隐式指定它对应的枚举类。
EnumMap 具有如下特征
EnumMap在内部以数组形式保存,所以这种实现形式非常紧凑、高效EnumMap根据key的自然顺序(即枚举值在枚举类中的定义顺序)来维护key-value对的顺序EnumMap不允许使用null作为key,看允许使用null作为value
public enum Season {
SPRING, SUMMER, FALL, WINTER
}
public class EnumMapTest {
public static void main(String[] args) {
EnumMap enumMap = new EnumMap(Season.class);
enumMap.put(Season.FALL, "秋高气爽");
enumMap.put(Season.SPRING, "春暖花开");
System.out.println(enumMap);
}
}
输出
{SPRING=春暖花开, FALL=秋高气爽}
Collections
Java 提供了一个操作Set、List 和 Map 等集合的工具类: Collections , 该工具类里提供了大量方法对集合元素进行排序、查询和修改等操作,还提供了将集合对象设置为不可变、对集合对象实现同步控制等方法
排序操作
Collections 提供了如下常用的静态方法用于对List 集合元素进行排序
-
void reverse(List list)反转指定List 集合中元素的顺序 -
void shuffle(List list)对 List 集合元素进行随机排序 -
void sort(List list)根据元素的自然顺序对指定List集合的元素按升序进行排序 -
void sort(List list,Comparator c)根据指定Comparator产生的顺序对List集合元素进行排序 -
void swap(List list, int i,int j)将指定List 集合中的i处元素和j处元素进行交换 -
void rotate(List list, int distance)当distance为整数时,将list集合的后distance个元素“整体” 移到前面;当distance为负数时, 将list集合的前distance个元素“整体” 移到后面
public class SortTest {
public static void main(String[] args) {
List nums = new ArrayList();
nums.add(20);
nums.add(19);
nums.add(-3);
nums.add(22);
nums.add(21);
System.out.println(nums);
// 反转顺序
Collections.reverse(nums);
System.out.println(nums);
// 从小到大排序
Collections.sort(nums);
System.out.println(nums);
// 随机排序
Collections.shuffle(nums);
System.out.println(nums);
// 将索引为2 和索引为4的元素交换位置
Collections.swap(nums, 2, 4);
System.out.println(nums);
// 将前两个元素移到集合末尾
Collections.rotate(nums,-2);
System.out.println(nums);
}
}
输出
[20, 19, -3, 22, 21]
[21, 22, -3, 19, 20]
[-3, 19, 20, 21, 22]
[22, 20, 21, -3, 19]
[22, 20, 19, -3, 21]
[19, -3, 21, 22, 20]
查找替换操作
Collections 还提供了如下常用的用于查找、替换的静态方法
int binarySearch(List list, Object key)使用二分搜索法搜索指定的List集合, 以获得指定对象在List集合中的索引。 如果要该方法可以正常工作,必须保证List 集合是有序状态。Object max(Collection coll)根据元素的自然顺序,返回给定集合中的最大元素Object min(Collection coll)根据元素的自然顺序,返回给定集合中的最小元素Object max(Collection coll,Comparator comp)根据Comparator指定的顺序,返回给定集合中的最大元素Object min(Collection coll,Comparator comp)根据Comparator指定的顺序,返回给定集合中的最大元素void fill(List list,Object obj)使用指定元素obj替换指定List集合中的 所有元素int frequency(Collection c,Object o)返回指定集合中指定元素的出现次数int indexOfSubList(List source,List target)返回子List对象在父List对象中第一次出现的位置索引,如果父List中没有出现这样的子List,则返回 -1int lastIndexOfSubList(List source,List target)返回子List对象在父List对象中最后一次出现的位置索引,如果父List中没有出现这样的子List,则返回 -1boolean replaceAll(List list,Object oldVal,Object newVal)使用一个新值newVal替换List对象的所有旧值oldVal
public class SearchTest {
public static void main(String[] args) {
List nums = new ArrayList();
nums.add(20);
nums.add(19);
nums.add(-3);
nums.add(22);
nums.add(21);
System.out.println(nums);
// 输出最大值
System.out.println(Collections.max(nums));
// 输出最小值
System.out.println(Collections.min(nums));
// 将集合中的所有19 替换为 17
Collections.replaceAll(nums,19,17);
System.out.println(nums);
// 获取-3在集合中出现的次数
System.out.println( Collections.frequency(nums,-3));
// 获取子集合在nums集合中首次出现的索引
System.out.println(Collections.indexOfSubList(nums,nums.subList(2,3)));
}
}
输出
[20, 19, -3, 22, 21]
22
-3
[20, 17, -3, 22, 21]
1
2
同步控制
Collections 类中提供了多个synchronizedXxx() 方法,该方法可以将指定集合包装成线程同步的集合
public class SynchronizedTest {
public static void main(String[] args) {
// 下面程序创建了四个线程安全的集合对象
Collection c = Collections.synchronizedCollection(new ArrayList());
List list = Collections.synchronizedList(new LinkedList());
Set set = Collections.synchronizedSet(new HashSet());
Map map = Collections.synchronizedMap(new HashMap<>());
}
}
设置不可变集合
Collections 提供了如下三类方法来返回一个不可变的集合
emptyXxx()返回一个空的、不可变的集合对象,此处的集合既可以是List、也可以是SortedSet、Set,还可以是Map、SortedMap等。singletonXxx()返回一个只包含指定对象(只有一个或一项元素)的、不可变的集合对象,此处的集合既可以是List、Set, 也可以是MapunmodifiableXxx()返回指定集合对象的不可变视图,此处的集合既可以是List、也可以是SortedSet、Set,还可以是Map、SortedMap等。
public class UnmodifiableTest {
public static void main(String[] args) {
List list = Collections.emptyList();
Set set = Collections.singleton("Java");
Map map = new HashMap();
map.put("语文",20);
Map unmodifiableMap = Collections.unmodifiableMap(map);
// 因为不可变,所以以下代码均会报错
list.add("12");
set.add("C#");
map.put("数学",12);
}
}
热门相关:冉冉心动 精灵掌门人 悠哉兽世:种种田,生生崽 重生之女将星 紫府仙缘